
Neural networks are mathematical constructs that generate predictions for complex problems. The basic unit of a neural network is a neuron, and each neuron serves a specific function. Bias serves two functions within the neural network – as a specific neuron type, called Bias Neuron, and a statistical concept for assessing models before training. Read on to learn how bias works, and how to avoid the most common bias challenges.
What Do We Mean by the Word Bias?
The word bias can have several meanings in neural networks. We’ll explore the two most common meanings:
- bias as a bias neuron
- bias as the bias vs. variance statistic
Bias Neuron in a Neural Network
A neural network is a mathematical construct that can approximate almost any function, and generate predictions for complex problems. A neural network is composed of neurons, which are very simple elements that take in a numeric input, apply an activation function to it, and pass it on to the next layer of neurons in the network. Below is a very simple neural network structure.
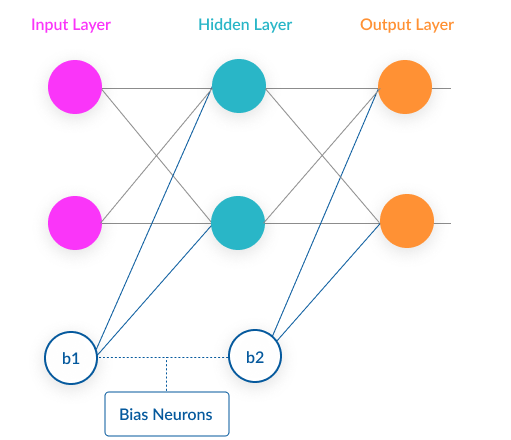
The bias neuron is a special neuron added to each layer in the neural network, which simply stores the value of 1. This makes it possible to move or “translate” the activation function left or right on the graph.
Without a bias neuron, each neuron takes the input and multiplies it by a weight, with nothing else added to the equation. So, for example, it is not possible to input a value of 0 and output 2. In many cases, it is necessary to move the entire activation function to the left or right to generate the required output values—this is made possible by the bias.
Although neural networks can work without bias neurons, in reality, they are almost always added, and their weights are estimated as part of the overall model.
Basic Concepts: the Training and Validation Error
Before we introduce bias and variance, let’s start with a few basic concepts:
Training Set – A training set is a group of sample inputs you can feed into the neural network in order to train the model. The neural network learns your inputs and finds weights for the neurons that can result in an accurate prediction.
Training Error – The error is the difference between the known correct output for the inputs and the actual output of the neural network. During the course of training, the training error is reduced until the model produces an accurate prediction for the training set.
Validation Set – A validation set is another group of sample inputs which were not included in training and preferably are different from the samples in the training set. This is a “real life exercise” for the model: Can it generate correct predictions for an unknown set of inputs?
Validation Error – The nice thing is that for the validation set, the correct outputs are already known. So it’s easy to compare the known correct prediction for the validation set with the actual model prediction—the difference between them is the validation error.
Practically, when training a neural network model, you will attempt to gather a training set that is as large as possible and resembles the real population as much as possible. You will then break up the training set into at least two groups: one group will be used as the training set and the other as the validation set.
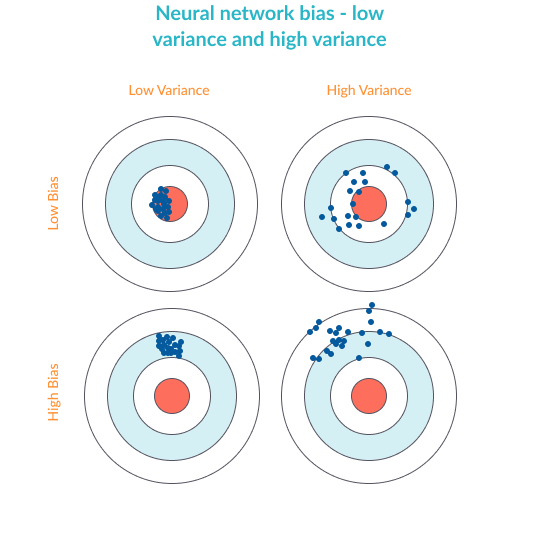
Definition of Bias vs. Variance
Bias—high bias means the model is not “fitting” well on the training set. This means the training error will be large. Low bias means the model is fitting well, and training error will be low.
Variance—high variance means that the model is not able to make accurate predictions on the validation set. The validation error will be large. Low variance means the model is successful in breaking out of its training data.
Overfitting and Underfitting
Overfitting in Neural Networks – Overfitting happens when the neural network is very good at learning its training set, but cannot generalize beyond the training set (known as the generalization problem).
The symptoms of Overfitting are:
Low bias – accurate predictions for the training set
High variance – poor ability to generate predictions for the validation set
Underfitting in Neural Networks – Underfitting happens when the network is not able to generate accurate predictions on the training set—not to mention the validation set.
The symptoms of Underfitting are:
High bias – poor predictions for the training set
High variance – poor predictions for the validation set
Managing Bias and Variance in Neural Networks
Now that we understand what bias and variance are and how they affect a neural network, let’s see a few practical ways to reduce bias and variance, and thus combat an overfitting or underfitting problem.
Methods to Avoid Overfitting in Neural Networks
The following are common methods used to improve the generalization of a neural network, so that it provides better predictive performance when applied to the unknown validation samples. The goal is to improve variance.
Retraining Neural Networks – Running the same neural network model on the same training set, but each time with different initial weights. The neural network with the lowest performance is likely to generalize the best when applied to the validation set.
Multiple Neural Networks – To avoid “quirks” created by a specific neural network model, you can train several neural networks in parallel, with the same structure but each with different initial weights, and average their outputs. This can be especially helpful for small, noisy datasets.
Early Stopping – Divide training data into a training set and a validation set and start training the model. Monitor the error on the validation set after each training iteration. Normally, the validation error and training set errors decrease during training, but when the network begins to overfit the data, the error on the validation set begins to rise. Early stopping occurs in one of two cases:
- If the training is unsuccessful, for example in a case where the error rate increases gradually over several iterations.
- If the training’s improvement is insignificant, for example, the improvement rate is lower than a set threshold.
Regularization – Regularization is a slightly more complex technique which involves modifying the error function (usually calculated as the sum of squares on the errors for the individual training or validation samples). Without getting into the math, the trick is to add a term to the error function, which is intended to decrease the weights and biases, smoothing outputs and making the network less likely to overfit.
Tuning Performance Ratio – The regularization term includes a performance ratio γ—this is a parameter that defines by how much the network will be smoothed out.
- You can manually set a performance ratio—if you set it to zero, the network won’t be regularized at all, and if you set it to 1 it will not fit the training data at all.
- It is also possible to automatically learn the optimal value of the performance ratio and then apply it to the network to achieve a balance.
Methods to Avoid Underfitting in Neural Networks—Adding Parameters, Reducing Regularization Parameter
What happens when the neural network is “not working”—not managing to predict even its training results? This is known as underfitting and reflects a low bias and low variance of the model. The following are common methods for improving fit—the goal is to increase bias and variance of the model.
Adding neuron layers or input parameters – For complex problems, adding neuron layers can help generate more complex predictions and improve the fit of the model. Another option, if relevant for your problem, is to increase the number of input parameters flowing into the model
Adding more training samples, or improving their quality – The more training samples you provide, and the better they represent the variance of parameters in the population at large, the better the network will learn.
Dropout – Another way to improve model fit is to randomly “kill” a certain percentage of the neurons in every training iteration. This can help improve generalization by ensuring that some of the information learned from the training set is randomly removed.
Decreasing regularization parameter – If you attempted to improve the model fit with regularization, you may have overdone it! Decrease the performance ratio to improve the fit and reduce bias.







{kind=link}