
Advances in the field of computer vision have been spearheaded by the adoption of Convolutional Neural Networks (CNNs). There are a number of related architectures available, among them the Region-CNN, used for object detection. R-CNN architectures can automatically recognize multiple objects in images but they are relatively slow. However, it is possible to build a Faster R-CNN architecture. Read on to learn how.
What is R-CNN?
Region-CNN (R-CNN), originally proposed in 2014 by Ross Girshik et. al., is a deep learning object detection algorithm that aims to find and classify multiple objects within an image.
There are two main problems R-CNN addresses:
– The algorithm doesn’t know in advance how many objects there will be in the image. This makes it difficult to use a Convolutional Neural Network (CNN), because the input is of variable length.
– There is a dilemma with regard to identifying objects in the image – you can arbitrarily choose a few regions and classify them, but then risk missing the important objects. Or check every possible region in the image, which would take too long to run.
R-CNN addresses the problems above using Selective Search. This involves sliding a window over the image to generate “region proposals” – areas where objects could possibly be found. The sliding window is in fact composed of several windows, each with different aspect ratios, to capture objects that appear in different sizes and are pictured from different angles. Using this sliding window, R-CNN generates 2,000 region proposals. It uses a greedy algorithm to recursively combine similar regions into one. The remaining list of regions is fed into a CNN – solving the variable input problem, because the number of areas for classification is now known.
Then, R-CNN may use one of several CNN architectures including AlexNet, VF, VGG, MobileNet or DenseNet to classify each of the candidate regions. Finally, it uses regression to predict the correct coordinates for the bounding box of each object (because the original Selective Search may not have accurately captured the entire object).
What Is Faster R-CNN?
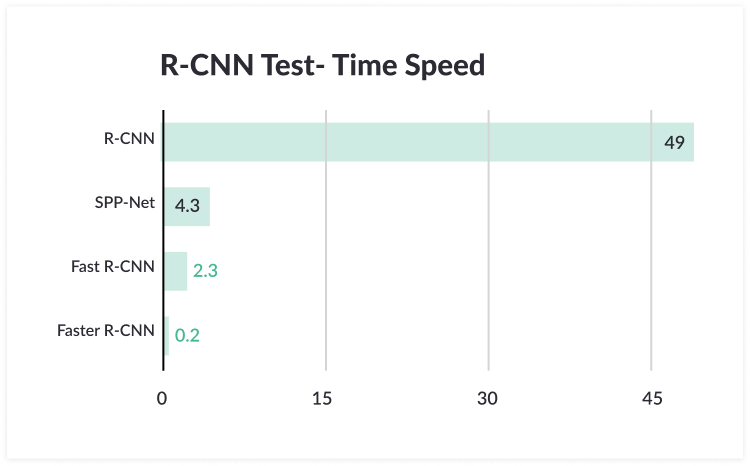
The main problem with R-CNN is that it is very slow to run. It can take 47 seconds to process one image on a standard deep learning machine, making it unusable for real-time image processing scenarios.
The main thing that slows down R-CNN is the Selective Search mechanism that proposes many possible regions and requires classifying all of them. In addition, the region selection process is not “deep” and there is no learning involved, limiting its accuracy. In 2015 Girshik proposed an improved algorithm called Fast R-CNN, but it still relied on Selective Search, limiting its performance.
Shoqing Ren et. al. proposed an improved algorithm called Faster R-CNN, which does away with Selective Search altogether and lets the network learn the region proposals directly. Faster R-CNN takes the source image and inputs it to a CNN called a Region Prediction Network (RPN). It considers a large number of possible regions, even more than in the original R-CNN algorithm, and uses an efficient deep learning method to predict which regions are most likely to be objects of interest.
The predicted region proposals are then reshaped using a Region of Interest (RoI) pooling layer. This layer itself is used to classify the images within each region and predict the offset values for the bounding boxes.
The image below shows the huge performance gains that Faster R-CNN achieves compared to the original R-CNN and Fast R-CNN proposed by Girshik’s team.
Object Detection with Faster R-CNN: How it Works
We will learn the steps of how we can implement Object Detection with Faster R-CNN. But, if you want to learn how to implement this at code level the you can learn at Code Implementation with Faster R-CNN.
Step 1: Anchors
Faster R-CNN uses a system of ‘anchors’, allowing the operator to define the possible regions that will be fed into the Region Prediction Network. An anchor is a box. The image below shows an image with size (600, 800) with nine anchors, reflecting three possible sizes and three aspect ratios━1:1, 1:2 and 2:1.
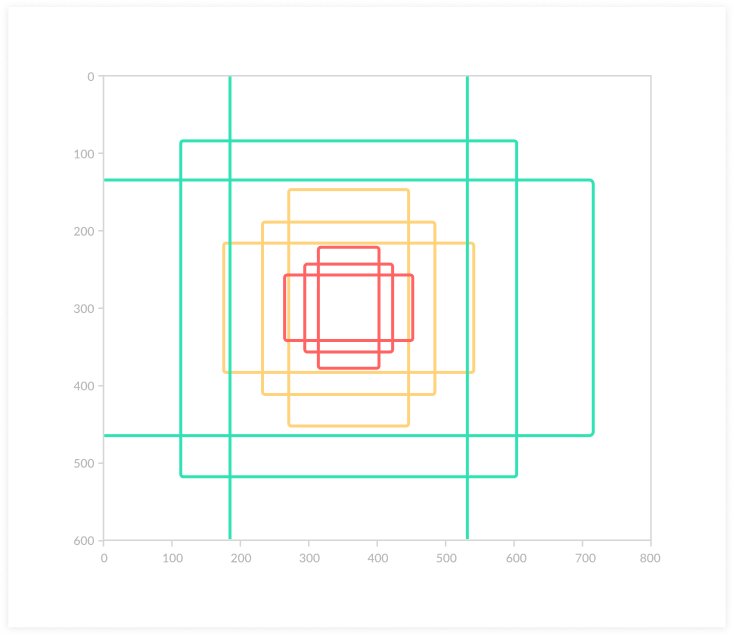
Given a stride of 16, meaning each of the anchors will slide over the image skipping 16 pixels at a time, there will be almost 18,000 possible regions. It is possible to fine-tune the anchors to suit the object detection problem at hand━for example if you need to identify people or cars from a distance in a surveillance video, you may focus the anchor on smaller sizes and appropriate aspect ratios.
Step 2: Region Proposal Network (RPN)
The algorithm feeds the possible regions, generated by the anchors defined in the previous step, into the RPN, a special CNN used for predicting regions with objects of interest. The RPN predicts the possibility of an anchor being background or foreground and refines the anchor or bounding box.
The training data of the RPN is the anchors and a set of ground-truth boxes. Anchors that have a higher overlap with ground-truth boxes should be labeled as foreground, while others should be labeled as background. The RPN convolves the image into features and considers each feature using the 9 anchors, with two possible labels for each (background or foreground).
Finally, the output is fed into a Softmax or logistic regression activation function, to predict the labels for each anchor. A similar process is used to refine the anchors and define the bounding boxes for the selected features. Anchors that are found to be foreground are passed to the next stage of the R-CNN algorithm.
Step 3: Region of Interest (RoI) pooling
The RPN provides proposed regions with different sizes. Each of these is a CNN feature map with a different size. Now the algorithm applies Region of Interest (RoI) pooling to reduce all the feature maps to the same size.
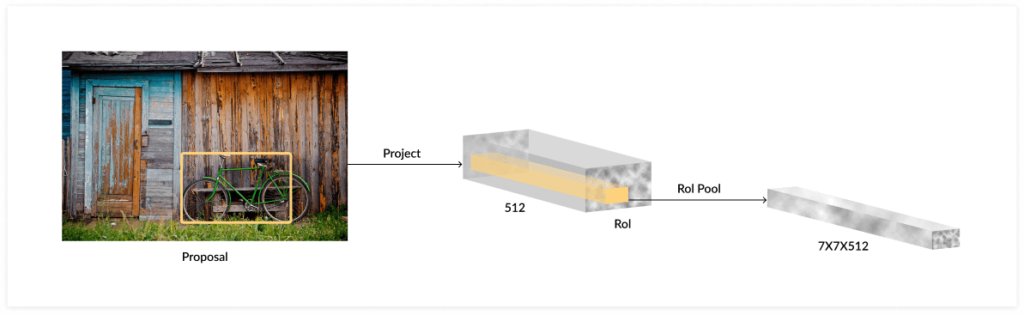
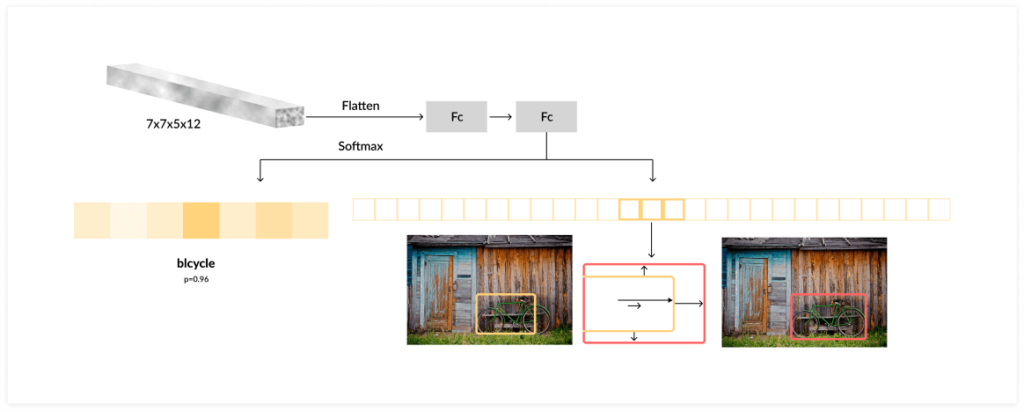
Faster R-CNN performs RoI pooling using the original R-CNN architecture. It takes the feature map for each region proposal, flattens it, and passes it through two fully-connected layers with ReLU activation. It then uses two different fully-connected layers to generate a prediction for each of the objects.





{kind=link}